Thema: Wie werden Daten im Plain-Text-Format (d.h. die Daten werden weder im HTML-Format noch im JSON-Format bereitgestellt), die auf einem externen Server bereitliegen, innerhalb von Home Assistant mittels eigenem Sensor abgerufen und weiterverarbeitet.
Daten im Plain-Text-Format werden, wie JSON-Daten auch, mittels rest: abgerufen (Dokumentation: https://www.home-assistant.io/integrations/sensor.rest/). Der wesentliche Unterschied liegt dabei dann in der Verwendung von value anstelle von value_json um das Ergebnis anzusprechen, und natürlich fällt der bequeme Zugriff auf JSON-Daten weg, hier muss auf andere Möglichkeiten zurückgegriffen werden um spezifische Datenbereiche auszufiltern.
Die Daten für dieses Beispiel:
Haus
Etage 1
- Wohnung 1-1: 42 Quadratmeter
- Wohnung 1-2: 30 QuadratmeterEtage 2
- Wohnung 2-1: 72 QuadratmeterKontakt
Name: Alice
Mail: alice@example.com
Ganz genau so schlicht als Text vorliegend, als Ziel setzen wir uns den Zugriff auf a) die Daten der Wohnungen aus Etage 1, b) den Zugriff auf die Kontaktdaten, Du bekommst hier also auch eine kleine Einführung in Möglichkeiten, Daten mittels sogenannten „regulären Ausdrücken“ zu filtern.
Der Code, der in der configuration.yaml gespeichert wird:
rest:
- resource: "URL-zu-den-Daten.txt"
sensor:
- name: "Demo PLAIN Wohnungen Etage 1"
value_template: "{{ value | regex_replace('(?s).*Etage 1','') | regex_replace('(?s)Etage 2.*','') }}"
- name: "Demo PLAIN Kontakt"
value_template: "{{ value | regex_replace('(?s).*Kontakt','') }}"
Achtung, Neustart notwendig, sonst wird der Sensor nicht angezeigt.
Sieht auf den ersten Blick sicher etwas kompliziert aus, und falls Du „einfach nur den kompletten Text haben möchtest“, dann kannst Du hier natürlich abkürzen, als value_template: schlicht value ausgeben und bist bereits fertig.
Zur Filterung verwenden wir hier „regex_replace“ (grundlegende Informationen zu den Optionen sind hier zu finden: https://www.home-assistant.io/docs/configuration/templating/#regular-expressions), aus den vollständigen Daten werden Bereiche ausgewählt und in diesem Fall durch „nichts“ ersetzt, also weggeschnitten. Filterung bedeutet hier, der Begriff regex_replace wird mittels vorangestelltem | an die zu verwertenden Daten angehängt (ggf. auch mehrfach): value | regex_replace('Suchbegriff','Ersatz').
Grundsätzlich ist bei regulären Ausdrücken davon auszugehen, dass die Kombination .* als „ein beliebiges Zeichen (der Punkt), und davon null bis unendlich viele (das Sternchen)“ bedeutet, also würde regex_replace('.*Etage 1','') eigentlich schon bedeuten „gesucht werden hier beliebig viele Zeichen von beliebiger Art bis zu und inklusive dem Begriff Etage 1“. Das kannst Du so auch immer dann verwenden, wenn Du eine einzelne Zeile Text auswerten möchtest.
Da es hier um mehrere Zeilen Text geht und Absätze regulär nicht als „beliebiges Zeichen“ behandelt werden muss um einen Modifikator erweitert werden. Davon gibt es so einige, hier interessant ist dieser: https://docs.python.org/3/library/re.html#re.S
Make the '.' special character match any character at all, including a newline; without this flag, '.' will match anything except a newline.
Corresponds to the inline flag (?s).
Kurz übersetzt, die Variante die sich „inline“, also innerhalb von regex_replace verwenden lässt, lautet (?s), und damit gilt der Punkt dann auch für Zeilenumbrüche, entsprechend lautet der vollständige Begriff dann regex_replace('(?s).*Etage 1',''). Damit sind die Daten schon zu einem Teil reduziert und sehen jetzt so aus:
- Wohnung 1-1: 42 Quadratmeter
- Wohnung 1-2: 30 QuadratmeterEtage 2
- Wohnung 2-1: 72 QuadratmeterKontakt
Name: Alice
Mail: alice@example.com
Ganz oben stehen nun also bereits die Daten, die für den ersten Sensor erwünscht sind, es geht noch darum, alles dahinter abzuschneiden. Besagtes „dahinter“ beginnt mit Etage 2 und geht bis zum Ende des Textes, der neue Suchbegriff ist also Etage 2.* und muss wiederum modifiziert werden für die Absätze, so dass die zweite Filterung so lautet: | regex_replace('(?s)Etage 2.*',''). Damit wurden in zwei Schritten alle unerwünschten Daten, sowohl vor als auch hinter dem gesuchten Bereich, durch „nichts“ ersetzt und damit weggeschnitten.
Für den zweiten Sensor ist das noch einfacher, da die gewünschten Daten ganz am Ende stehen, es braucht also nur eine Filterung, die, wieder mit Rücksichtnahme auf die Absätze, alles inklusive dem Begriff „Kontakt“ entfernt.
Die Sensoren im Screenshot:
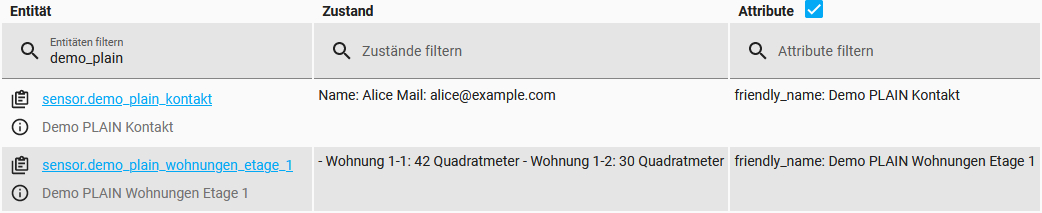
Sind bei den Ergebnissen der Sensoren noch Absätze „drumherum“, so werden diese automatisch ausgefiltert, deshalb ist es auch absolut unproblematisch die zweite Filterung erst ab „Etage 2“ einsetzen zu lassen und den Absatz dazwischen schlicht zu ignorieren.